 This website was archived on January 11, 2020 and is no longer updated.
This website was archived on January 11, 2020 and is no longer updated.
C1: Overview of data collection process
This part of OrMaCode aims to translate the principles of the Code of Practice into practical guidelines for current and prospective data collectors.
The data collection process can be divided into three basic steps:
- data development: the design, planning and organisation of the statistical data collection process, within the given institutional environment;
- data production: the actual data collection and data processing used to produce meaningful statistical information, also known as the statistical process or statistical production process;
- dissemination of statistical information: the activities related to publishing and making the statistical information (statistical output) available to the public, eventually with restricted access to some users or subscribers.
To achieve data quality, each step in the data collection process needs to be approached within the context of quality management (see Figure C.1-1).
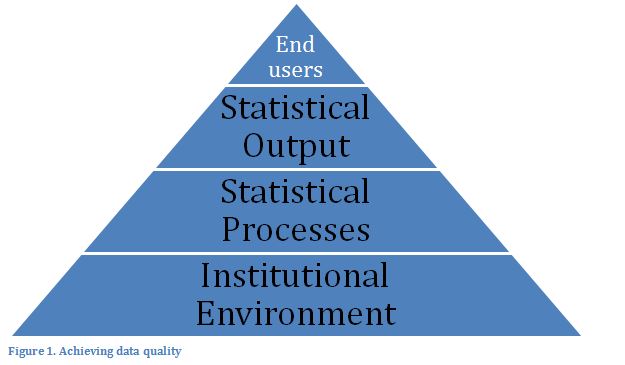
Statistical output quality is achieved through the statistical data collection process. Data development, i.e., the design, planning and organisation of statistical processes, is essential to achieve data quality. A statistical process will never maximise all of the quality components of a given statistical output at one time. For example, expert assessment might help to achieve the timeliness for the publication of statistical information at the expense of accuracy. Finally, end users will probably have a different perception of data quality than the data producers. Therefore, although user perception is dependent on the objective data quality achieved by the statistical processes, the users will often have subjective views and priorities in their assessing of the data quality. For example, among organic sector stakeholders, some believe that “inaccurate but timely data is better than no data”. User perception needs therefore to be considered when planning organic market data collection, as how the users actually perceive the quality of the statistical output is an essential part of any data quality assessment (Ehling and Koerner, 2007).
Data quality management starts from the development of survey instruments and questionnaires, and continues throughout the data production process itself, and then beyond, once the data are published. The costs of achieving data quality need to be balanced with the costs of producing data of poor quality (Table C.1-1).
Table C.1-1: A taxonomy of the data quality costs (Haug et al, 2011)
Data quality costs |
Costs caused by low data quality |
Direct costs | Verification costs |
| Re-entry costs | |||
| Compensation costs | |||
Indirect costs | Costs based on lower reputation | ||
| Costs based on wrong decisions or actions | |||
| Sunk investment costs | |||
Costs of improving or assuring data quality |
Prevention costs | Training costs | |
| Monitoring costs | |||
| Standard development and deployment costs | |||
Detection costs | Analysis costs | ||
| Reporting costs | |||
Repair costs | Repair planning costs | ||
| Repair implementation costs |
In the next sections, specific guidelines will be provided to apply Principles 7, 8, 9 and 10 of the Code of Practice, to achieve better quality (as defined in Principles 11-15) for the production of organic market data.
With respect to the data collection process, these issues will be addressed in the following sections:
Data collection methods need to be coherent with the type of data and the purpose of the data collection (section C2).
- Standard tools should be developed for the collection and analysis of the data, and these tools should be harmonised with existing European definitions, nomenclatures and classifications (section C3).
- Data analysis and processing need to be appropriate for the final use (i.e., publication, modelling), to make the statistical information relevant to the users. Data quality analysis is time consuming, but it helps to reduce errors in the data. Therefore, consistency checks that serve to screen the quality of the data are highly recommended to all organisations and individuals engaged in the collection and dissemination of organic market data. Data quality checks need to be prioritised according to the user needs, and whenever inconsistent data are found, better data should be sought. In addition, if only expert estimates are available, it is highly recommended to carry out cross-checks against other sources (section C4);
- Achieving higher data quality might impact on publication times. Accuracy needs to be balanced with timeliness and punctuality of data publication. If inconsistencies cannot be resolved when the data is being analysed, this should be indicated when disseminating the data. In addition, users might have expectations of open access to all kinds of organic market data. However, as the development, production and publication of good quality data are costly, data collectors need to identify the appropriate business model to provide adequate funding for the process (section C5);
- Sample size, sampling method, and coverage of the ‘universe’ have a strong impact on the resulting data quality, in terms of both relevance and accuracy. Although these issues are partially discussed in section C2, Part D further explores them.